
说是前缀和 & 差分,但本篇文章只给了 2 道前缀和的题目,嘛,没差,都那样。
这篇文章讲的很好,图文并用:《前缀和与差分算法》
# 前缀和 & 差分
| 概念 | 核心思想 | 特点 | 常见用途 | 示例 |
|---|---|---|---|---|
| 前缀和(Prefix Sum) | 通过 “累计求和” 快速得到区间和。 |
|
统计区间和、区间平均值、二维前缀和矩阵 | 已知数组 a = [1,2,3,4] 构造 sum[i] = sum[i-1] + a[i] 要算 [2,4] 的和,只需 sum[4]-sum[1]=9 |
| 差分(Difference Array) | 通过 “记录变化量” 实现快速区间修改。 |
|
区间加法、区间赋值、模拟前缀变化 | 若 a = [1,1,1,1] 要让 [2,3] 每个加 2:diff[2]+=2, diff[4]-=2 最后求前缀和得 [1,3,3,1] |
- 它们是互为逆运算:
前缀和是「累加」,差分是「还原」。
特征:
- 当你需要频繁查询区间和 → 用 前缀和。
- 当你需要频繁修改区间值 → 用 差分。
- 在复杂题目中,常常需要两者结合使用。
# 二维前缀和 & 二维差分
| 概念 | 核心思想 | 特点 | 常见用途 | 示例 |
|---|---|---|---|---|
| 二维前缀和(2D Prefix Sum) | 将 “累加” 扩展到矩阵中,用于快速求任意矩形区域的和。 |
|
图像区域和、子矩阵统计、积分图(Integral Image) | 构造:sum[i][j] = a[i][j] + sum[i-1][j] + sum[i][j-1] - sum[i-1][j-1] 查询任意矩形 (x1,y1)-(x2,y2) 的和:S = sum[x2][y2] - sum[x1-1][y2] - sum[x2][y1-1] + sum[x1-1][y1-1] |
| 二维差分(2D Difference Array) | 通过 “标记变化角点” 来实现矩形区域的快速修改。 |
|
区域增量操作、图像处理、区域更新 | 若要让矩形 (x1,y1)-(x2,y2) 全部加 k :diff[x1][y1] += k diff[x2+1][y1] -= k diff[x1][y2+1] -= k diff[x2+1][y2+1] += k 最后通过前缀和还原矩阵: a[i][j] = diff[i][j] + a[i-1][j] + a[i][j-1] - a[i-1][j-1] |
# 快速记忆
- 二维前缀和:查得快,改得慢。
- 二维差分:改得快,查得慢。
- 依旧是互为逆过程,只不过 “区间” 变成了 “矩形”。
# 应用举例
| 操作 | 适合方法 | 示例思路 |
|---|---|---|
| 查询一张图像中某个区域的像素总和 | 二维前缀和 | 预处理整张图,再 O (1) 查询区域和 |
| 同时给一块区域所有元素加上某个值 | 二维差分 | 只需在矩形四个角更新,最后整体还原 |
# 🪄 小提示
- 前缀和公式和差分公式互为逆操作。
- 实际编程时注意 数组越界(所以我建议直接开大一圈的数组,就是 n+2)。
- 二维题中常常出现 “坐标从 1 开始” 的设定,请保留
0行0列作为辅助边界。
Counting Rectangles[Medium]
# CF1722E Counting Rectangles
# 题目描述
你有 个矩形,第 个矩形的高为 ,宽为 。
你将会被询问 次,每次询问的形式为 。
对于每个询问,输出你拥有的所有矩形中,能够容纳一个高为 、宽为 的矩形,并且也能被一个高为 、宽为 的矩形容纳的所有矩形的面积之和。换句话说,输出所有满足 且 的 的 。
请注意,如果两个矩形有相同的高或宽,则它们不能互相容纳。另外,矩形不能旋转。
还要注意,对于某些测试点,答案可能无法用 32 位整数类型存储,因此你应该在你的编程语言中至少使用 64 位整数类型(如 C++ 的 long long)。
# 输入格式
输入的第一行包含一个整数 (),表示测试用例的数量。
每个测试用例的第一行包含两个整数 (;),分别表示你拥有的矩形数量和询问数量。
接下来 行,每行包含两个整数 (),表示第 个矩形的高和宽。
接下来 行,每行包含四个整数 (),表示每个询问的描述。
所有测试用例中 的总和不超过 ,所有测试用例中 的总和不超过 。
# 输出格式
对于每个测试用例,输出 行,第 行输出第 个询问的答案。
# 输入输出样例
# 输入
1 | 3 |
# 输出
1 | 6 |
# 说明 / 提示
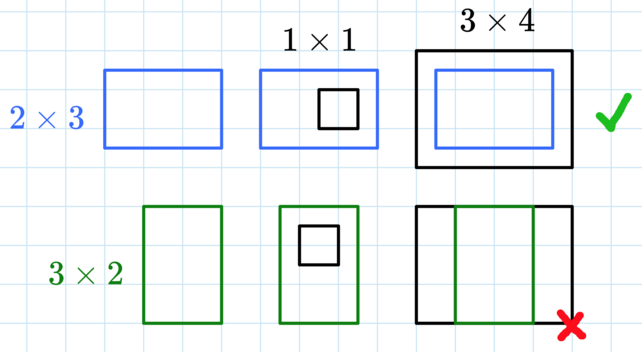
在第一个测试用例中,只有一个询问。我们需要找到所有能够容纳 矩形并且能被 矩形容纳的矩形的面积之和。
只有 的矩形满足条件,因为 (比较高)且 (比较宽),所以 的矩形可以放进去;同时 (比较高)且 (比较宽),所以它也能被 的矩形容纳。 的矩形太高,无法放进 的矩形。总面积为 。
# 前缀和解法
1 |
|
Triple[hard]
# Problem Description
To prevent you from getting bored after AK, wlk has come up with a question adapted from “Quadruple”.
You have a string s of length n (1-indexed), and the string contains only characters 'A' , 'C' , and 'M' .
You want to do some practice with this string.
There are q queries in total.
In each query, two integers l, r are given.
Let string t be the substring of s starting at index l and ending at index r.
Then ask how many different kinds of arrays a are good.
# Definition of a good array
An array a is good if and only if the following conditions are met:
- The length of the array is 3.
- t[a₁] = ‘A’, t[a₂] = ‘C’, t[a₃] = ‘M’.
- a₁ < a₂ < a₃.
Two arrays a, b are different if and only if there exists at least one number
k (1 ≤ k ≤ 3) such that aₖ ≠ bₖ.
As the answer can be large, find it modulo 998244353.
# Input
-
The first line contains two integers n, q
(1 ≤ n ≤ 2×10⁶, 1 ≤ q ≤ 2×10⁵) —
representing the length of the string s and the number of queries. -
The second line contains the string s.
-
The next q lines each contain two integers l, r
(1 ≤ l ≤ r ≤ n).
# Output
For each query, print a single line containing the answer —
the number of good arrays modulo 998244353.
| Input | Output |
|---|---|
| 6 3 AACCMM 1 6 2 6 2 5 |
8 4 2 |
# 前缀和
1 |
|